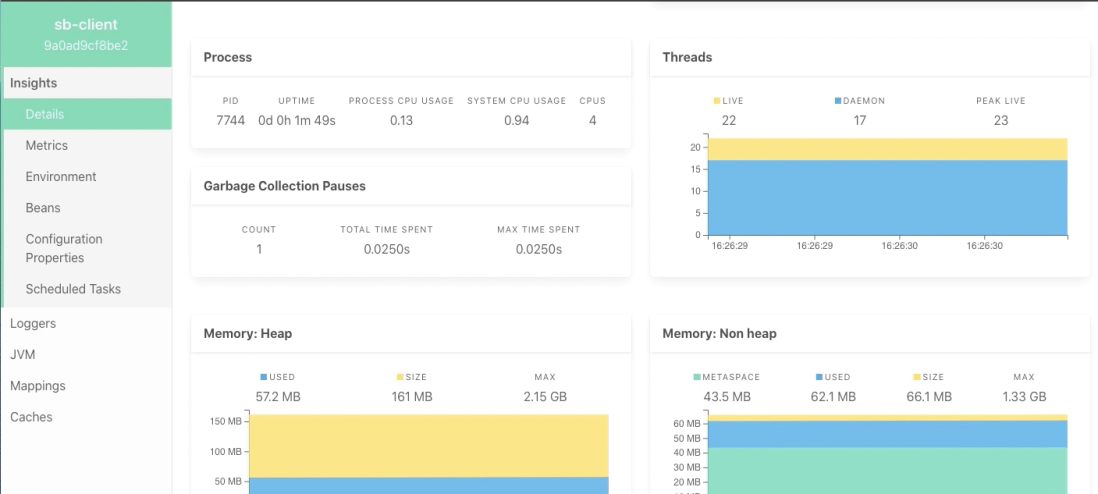
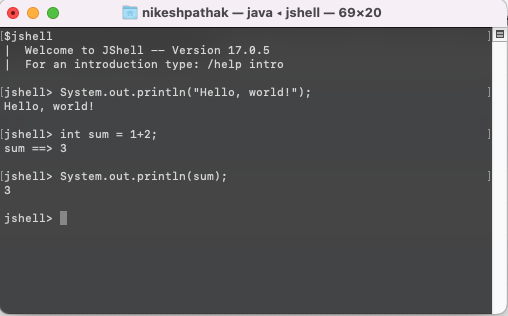
Hi Everyone,
In Part 1, We’ve covered till Java 14 changes in Part 1. Let’s pick up from there.
Note – Here I have highlighted only important features and skipped few features that has minor improvement across multiple versions.
Let’s drive in.
Java 15
Sealed Classes and Interfaces (Preview): Java 15 introduced sealed classes and interfaces, which are new features that allow you to restrict which classes or interfaces can extend or implement a given class or interface. This can be useful for modeling domain concepts, improving the security of libraries, and making your code more readable and maintainable.
example – sealed interface Drawable permits Circle, Square, Rectangle {}
Hidden Classes: Java 15 introduced hidden classes, which are classes that cannot be used directly by the bytecode of other classes. Hidden classes are intended to be used by frameworks that generate classes at runtime and use them indirectly via reflection. A hidden class is defined as a member of an access control nest, and it can be unloaded independently of other classes.
Hidden classes have a number of benefits, including:
- Reduced memory usage: Hidden classes can help to reduce memory usage by avoiding the need to load classes that are only needed for a short time.
- Improved performance: Hidden classes can help to improve performance by reducing the overhead of loading and unloading classes.
- Increased security: Hidden classes can help to improve security by making it more difficult for attackers to access classes that are not intended to be exposed.
Here is an example of how to use a hidden class:
// Define a hidden class
@NestMember
private static class HiddenClass {}
// Create a new instance of the hidden class
HiddenClass hiddenClass = new HiddenClass();
// Use the hidden class
// ...
// Unload the hidden class
Lookup lookup = MethodHandles.lookup();
lookup.removeClass(HiddenClass.class);
Hidden classes are a powerful new feature in Java 15 that can help you to reduce memory usage, improve performance, and increase security. However, it is important to use hidden classes with caution, as they can also make your code more difficult to understand and maintain.
Here are some examples of how hidden classes can be used:
- A web framework could use hidden classes to generate classes that represent dynamic resources, such as web pages or API endpoints.
- A compiler could use hidden classes to generate classes that represent the intermediate representation of a program.
- A security framework could use hidden classes to generate classes that represent security policies or permissions.
Overall, hidden classes are a valuable new feature in Java 15 that can make your code more efficient and secure. However, it is important to use them with caution and to understand the implications of using them.
Java 16
Foreign-Thread Context: Java 16 introduced the Foreign-Thread Context (FTC) API, which allows Java threads to interact with threads from other programming languages. This can be useful for developing applications that need to interact with native code or with code that is written in other programming languages.
The FTC API provides a number of features that make it easy to interact with foreign threads, including:
- Thread scheduling: The FTC API allows you to schedule foreign threads to run on Java threads. This can be useful for offloading work to other threads or for running code that is not Java-compatible on Java threads.
- Thread synchronization: The FTC API provides a number of features for synchronizing foreign threads with Java threads. This can be useful for preventing race conditions and for ensuring that data is shared safely between foreign threads and Java threads.
- Thread communication: The FTC API provides a number of features for communicating between foreign threads and Java threads. This can be useful for passing data between foreign threads and Java threads or for signaling events between foreign threads and Java threads.
The FTC API is still under development, but it has the potential to revolutionize the way that Java applications interact with other languages and native code.
Vector API (third incubator): The Vector API is a new Java API that provides a more efficient way to process data vectors. A data vector is a collection of elements of the same type, such as an array of integers or a list of strings.
The Vector API provides a number of features that make it more efficient to process data vectors, including:
- Vectorized operations: The Vector API allows you to perform operations on data vectors in parallel. This can significantly improve the performance of your code, especially when processing large data sets.
- Automatic vectorization: The Vector API can automatically vectorize loops and other code constructs. This can save you the time and effort of manually vectorizing your code.
- SIMD support: The Vector API supports SIMD instructions, which can further improve the performance of your code on modern processors.
- Improved performance: Vector operations can be performed much faster than traditional for-loops, because they operate on multiple elements of an array at the same time.
- Reduced code complexity: The Vector API provides a simplified interface for performing vector operations, which can help to reduce the complexity of your code.
- Increased portability: The Vector API is designed to be portable to different hardware platforms, which means that your code will be able to take advantage of the vector processing capabilities of your hardware.
example –
int[] array = {1, 2, 3, 4, 5};
Vector vector = Vector.of(array);
int sum = vector.add();
exp-2
import java.util.Vector;
public class VectorExample {
public static void main(String[] args) {
// Create a vector of integers
Vector<Integer> vector = new Vector<>();
vector.add(1);
vector.add(2);
vector.add(3);
// Sum the elements of the vector using the vectorized sum() operation
int sum = vector.stream().sum();
// Print the sum of the elements of the vector
System.out.println(sum);
}
}
To use the Vector API, you simply need to import the java.util.vector package and create a Vector object. You can then add elements to the Vector object and perform odperations on the elements of the Vector object using the vectorized operations provided by the Vector API.
Java 17
Enhanced pseudo-random number generators: Java 17 introduced a new API for pseudo-random number generators (PRNGs). This new API provides a number of benefits, including:
- Improved performance: The new PRNG API provides improved performance over the legacy PRNG API.
- More flexibility: The new PRNG API provides more flexibility for generating pseudo-random numbers. For example, the new API allows you to specify the desired seed and algorithm for generating pseudo-random numbers.
- Increased security: The new PRNG API provides increased security for generating pseudo-random numbers. For example, the new API uses more secure algorithms for generating pseudo-random numbers.
To use the new PRNG API, you simply need to create an instance of a Random Generator object. You can then use the Random Generator object to generate pseudo-random numbers of various types, such as integers, floats, and doubles.
Here is an example of how to use the new PRNG API to generate a random integer:
RandomGenerator randomGenerator =RandomGenerator.of("Xoroshiro128PlusPlus");
int randomNumber = randomGenerator.nextInt();
Java 18
UTF-8 by default: Java 18 makes UTF-8 the default charset for all implementations, operating systems, locales, and configurations. This means that all of the APIs that depend on the default charset will behave consistently without the need to set the file. encoding system property or to always specify charset when creating appropriate objects.
Simple web server: Java 18 introduced a new Simple Web Server command-line tool (jwebserver) that can be used to serve static files from the current directory and its subdirectories. This is a useful tool for prototyping, debugging, and testing web applications.
To start the Simple Web Server, simply run the jwebserver command in the directory that contains the static files that you want to serve. The Simple Web Server will then start listening on port 8000 by default.
To access the Simple Web Server, simply navigate to http://localhost:8000 in your web browser. You should then see a listing of the static files that are available.
To start the simple web server, simply open a terminal window and navigate to the directory where you want to serve the static files from. Then, run the following command:
jwebserver
This will start the web server on port 8000. You can then access the web server by visiting http://localhost:8000 in your web browser.
If you want to serve the static files from a different directory, you can specify the directory path as an argument to the jwebserver command. For example, the following command will start the web server on port 8000 and serve the static files from the /path/to/static/files directory:
jwebserver /path/to/static/files
You can also specify a different port number as an argument to the jwebserver command. For example, the following command will start the web server on port 9000:
jwebserver --port 9000
The simple web server in Java 18 is a useful tool for serving static files. It is easy to use and can be used to quickly and easily create a simple web server.
Code snippets in Java API documentation: Java 18 introduced a new @snippet tag for the JavaDoc’s Standard Doclet, to simplify the inclusion of example source code in API documentation.
The @snippet tag can be used to declare both inline snippets, where the code fragment is included within the tag itself, and external snippets, where the code fragment is read from a separate source file.
Here is an example of an inline snippet:
/**
* Calculates the sum of two integers.
*
* @param x The first integer.
* @param y The second integer.
* @return The sum of `x` and `y`.
*/
public int add(int x, int y) {
// @snippet java
return x + y;
}
Here is an example of an external snippet:
/**
* Calculates the factorial of a number.
*
* @param n The number.
* @return The factorial of `n`.
*/
public int factorial(int n) {
// @snippet factorial.java
if (n == 0) {
return 1;
} else {
return n * factorial(n - 1);
}
}
Reimplemented core reflection with method handles: Java 18 reimplemented the core reflection API using method handles. This was done to improve the performance and security of the reflection API.
Method handles are a more powerful and flexible way to manipulate the members of a class dynamically. They are also more efficient, as they can avoid the need to generate bytecode at runtime.
The reimplemented reflection API is still fully compatible with the existing reflection API. This means that existing code that uses reflection will continue to work without any changes.
Here are some of the benefits of reimplementing the core reflection API with method handles:
- Improved performance: The reimplemented reflection API can be significantly faster than the old reflection API, especially for complex reflection operations.
- Reduced memory usage: The reimplemented reflection API uses less memory than the old reflection API, as it does not need to generate bytecode at runtime.
- Improved security: The reimplemented reflection API is more secure than the old reflection API, as it makes it more difficult for attackers to exploit reflection vulnerabilities.
Overall, the reimplemented reflection API in Java 18 is a significant improvement over the old reflection API. It is faster, more efficient, and more secure.
Here are some examples of how to use the reimplemented reflection API in Java 18:
import java.lang.invoke.MethodHandle;
import java.lang.invoke.MethodHandles;
import java.lang.invoke.MethodType;
public class Example {
public static void main(String[] args) throws Throwable {
User user = new User("TestUser", 25);
// Obtain method handles to access and modify field
MethodHandle getNameHandle = MethodHandles.lookup()
.findGetter(User.class, "name", String.class);
MethodHandle setNameHandle = MethodHandles.lookup()
.findSetter(User.class, "name", String.class);
String currentName = (String) getNameHandle.invokeExact(user);
System.out.println("Current name: " + currentName);
setNameHandle.invokeExact(user, "Nikesh");
// get the updated field
String updatedName = (String) getNameHandle.invokeExact(user);
System.out.println("Updated name: " + updatedName);
}
}
class User {
String name;
int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
}
//output -
Current name: TestUser
Updated name: Nikesh
Internet-address resolution SPI : Java 18 introduced a new Internet-Address Resolution SPI that allows applications to plug in their own custom Internet address resolution logic. This can be useful for applications that need to resolve Internet addresses in a specific way, such as for security reasons or to support custom DNS servers.
The Internet-Address Resolution SPI is based on the Service Provider Interface (SPI) pattern. This means that applications can register their own custom Internet address resolution providers with the SPI. When an application needs to resolve an Internet address, it will consult the SPI to find a registered provider and then use that provider to resolve the address.
To register a custom Internet address resolution provider with the SPI, you need to create a class that implements the InternetAddressResolver interface. This interface has a single method, resolve(), which takes an Internet address string as input and returns an Internet address object.
Here is an example of a custom Internet address resolution provider that resolves Internet addresses using a custom DNS server:
import java.net.InetAddress;
import java.net.InternetAddressResolver;
public class CustomInternetAddressResolver implements InternetAddressResolver {
private final String dnsServerAddress;
public CustomInternetAddressResolver(String dnsServerAddress) {
this.dnsServerAddress = dnsServerAddress;
}
@Override
public InetAddress resolve(String hostname) throws Exception {
// Resolve the hostname using the custom DNS server
return InetAddress.getByName(hostname, dnsServerAddress);
}
}
//To register this custom provider with the SPI, you would call the following code:
java.net.InetAddressResolver.register("com.example.CustomInternetAddressResolver");
Java 19
Project loom: Project Loom is an experimental project in Java 19 that aims to bring lightweight concurrency to Java. It does this by introducing a new programming model called virtual threads, which are more lightweight and efficient than traditional Java threads.
Virtual threads are managed by the JVM and are not tied to OS threads. This means that the JVM can schedule virtual threads much more efficiently than OS threads, and it can also create and manage many more virtual threads without impacting performance.
Project Loom also provides a number of other features that make it easier to write concurrent programs, such as:
- Structured concurrency: Structured concurrency allows you to write concurrent programs in a more structured and sequential way. This can make your code more readable and maintainable.
- Tail calls: Tail calls allow you to optimize recursive functions by avoiding the need to stack frames. This can improve the performance of your concurrent programs.
- Delimited continuations: Delimited continuations allow you to capture the state of a running program and then later resume the program from that state. This can be useful for writing concurrent programs that need to handle errors or cancellations gracefully.
Project Loom is still under development, but it has the potential to revolutionize the way that concurrent programs are written in Java.
Here are some of the benefits of using Project Loom:
- Improved performance: Virtual threads can be scheduled much more efficiently than OS threads, and the JVM can also create and manage many more virtual threads without impacting performance.
- Reduced memory usage: Virtual threads are much more lightweight than OS threads, so they use less memory.
- Improved scalability: Project Loom can help applications to scale to larger numbers of concurrent users.
- Simplified concurrency: Project Loom makes it easier to write concurrent programs by providing features such as structured concurrency, tail calls, and delimited continuations.
Overall, Project Loom is a promising new project that has the potential to make Java a more efficient and scalable platform for developing concurrent applications.
Foreign function & memory API: The Foreign Function & Memory (FFM) API is a new API in Java 19 that enables Java programs to interoperate with code and data outside of the Java runtime. This API enables Java programs to call native libraries and process native data without the brittleness and danger of JNI.
The FFM API is based on two earlier incubating APIs: the Foreign-Memory Access API (JEPs 370, 383, and 393) and the Foreign Linker API (JEP 389).
The FFM API has a number of benefits, including:
- Improved safety: The FFM API is safer than JNI because it provides a number of features that help to prevent common errors, such as buffer overflows and memory leaks.
- Improved performance: The FFM API is more performant than JNI because it avoids the need to generate and manage JNI bridges.
- Increased flexibility: The FFM API is more flexible than JNI because it provides a variety of ways to interoperate with native code and data.
Here is an example of how to use the FFM API to call a native function:
import java.lang.foreign.Linker;
import java.lang.foreign.MemoryAddress;
import java.lang.foreign.MemorySession;
public class FfmExample {
public static void main(String[] args) throws Exception {
// Get the address of the native function
MemoryAddress functionAddress = Linker.getInstance().loadLibrary("mylib").lookupFunction("my_function");
// Create a memory session
MemorySession session = MemorySession.open();
// Allocate memory for the arguments to the native function
MemoryAddress[] arguments = new MemoryAddress[1];
arguments[0] = session.allocateArray(Integer.TYPE, 1);
// Call the native function
Linker.getInstance().downcall(functionAddress, arguments);
// Free the memory allocated for the arguments to the native function
session.close();
}
}
The Foreign Function & Memory (FFM) API is a new API in Java 19 that enables Java programs to interoperate with code and data outside of the Java runtime. This API enables Java programs to call native libraries and process native data without the brittleness and danger of JNI.
The FFM API is based on two earlier incubating APIs: the Foreign-Memory Access API (JEPs 370, 383, and 393) and the Foreign Linker API (JEP 389).
The FFM API has a number of benefits, including:
- Improved safety: The FFM API is safer than JNI because it provides a number of features that help to prevent common errors, such as buffer overflows and memory leaks.
- Improved performance: The FFM API is more performant than JNI because it avoids the need to generate and manage JNI bridges.
- Increased flexibility: The FFM API is more flexible than JNI because it provides a variety of ways to interoperate with native code and data.
The FFM API is still under development, but it has the potential to revolutionize the way that Java programs interact with native code and data.
Here are some additional benefits of using the FFM API in Java 19:
- It can help to reduce the amount of JNI code that needs to be written.
- It can make Java programs more portable and efficient.
- It can open up new possibilities for Java programs to interact with native libraries and data.
Java 21
Structured concurrency: Structured concurrency is a programming model for writing concurrent code in a more structured and sequential way. This makes it easier to read, understand, and maintain concurrent code.
Structured concurrency is based on the idea of using a structured task scope to manage the execution of concurrent tasks. A structured task scope is a container for concurrent tasks that provides a number of features, including:
- Task execution: The structured task scope provides a way to fork new tasks and to wait for tasks to complete.
- Task cancellation: The structured task scope provides a way to cancel tasks.
- Error handling: The structured task scope provides a way to handle errors in tasks.
Structured concurrency is a new feature in Java 19 that is still under development. However, it has the potential to revolutionize the way that concurrent programs are written in Java.
Java 21 includes the Structured Concurrency (Second Incubator) feature, which is a preview feature that extends the Structured Concurrency feature introduced in Java 19. The Second Incubator feature adds a number of new features, including:
- Subtask cancellation: The ability to cancel subtasks of a structured task.
- Subtask joining: The ability to wait for all subtasks of a structured task to complete before returning.
- Subtask results: The ability to get the results of all subtasks of a structured task.
- Improved error handling: Improved support for handling errors in structured tasks.
The Second Incubator feature is still under development, but it has the potential to make it even easier to write concurrent programs in Java.
Here is an example of how to use the Structured Concurrency (Second Incubator) feature to cancel a subtask:
import java.util.concurrent.StructuredTaskScope;
public class StructuredConcurrencyExample {
public static void main(String[] args) throws Exception {
// Create a structured task scope
StructuredTaskScope scope = new StructuredTaskScope.ShutdownOnFailure();
// Fork a subtask
scope.fork(() -> {
// Do some work
// ...
});
// Cancel the subtask
scope.cancel();
// Join the structured task scope
scope.join();
}
}
If the subtask is successfully cancelled, the join() method will return immediately. Otherwise, the join() method will wait for the subtask to complete before returning.
The Structured Concurrency (Second Incubator) feature is a valuable new feature in Java 21 that can make it easier to write robust and efficient concurrent programs.
Thanks for reading. you can connect me @linkedin